計畫成員:蘇黎、林仁俊
目前的生成式人工智慧 (generative AI) 技術在電影、人物動畫等蘊含主題、敘事(storytelling)並需整合影音資訊之內容生成仍有巨大技術門檻,故此類製作仍須仰賴大量人工,並需要使用人體動作捕捉系統 (human motion capture; MOCAP) 等昂貴的技術。近年來,虛擬音樂家及VTuber等虛擬偶像蔚為風潮,也強化了電影、人物動畫之自動生成需求。因此,從2022年起,我們開始執行由中研院補助的主題計畫「基於深度學習的多媒體影音內容理解與生成」(2022/01 – 2024/12)。在計畫執行的前一年中,本研究團隊優先處理兩項技術:第一為從單鏡頭視頻中估計人物的三維姿勢與形體,以減低對人體動作捕捉技術的依賴;第二則為以音樂內容作為提示 (prompt) 的虛擬音樂家演奏視訊生成系統,其整合了肢體動作、手指位置、臉部表情和運鏡等四類人物動畫資訊的生成技術。
以音樂內容作為提示的虛擬音樂家演奏視訊生成系統
我們以小提琴演奏為例,處理四種跟虛擬音樂家演奏視訊關聯的資訊:肢體動作、指法、臉部表情和運鏡,目的為產生與音樂相符的演奏影片。本實驗室在過去幾年中持續收集累積音樂與肢體動作的資料庫,也已經完成從音樂生成三維肢體動作骨架點和小提琴指法的模型,加上支援人機合奏的自動伴奏系統,結果皆已發表在ACM Multimedia和ISMIR等頂尖會議,並實際使用於公開演出。最近我們進一步完成了兩個新的模型:臉部表情生成模型和運鏡模型。
在臉部表情生成模型中,我們將訓練資料中小提琴家所演奏的音樂訊號對應到其臉部表情變化。我們訓練一種3D卷積神經網路(3D convolutional neural network, 3D CNN),其輸入為音樂訊號、輸出為人臉關鍵點(facial landmarks),目前已知優於其他音訊到人臉關鍵點的生成模型,其成果將發表於 IEEE ICASSP 2023。此階段產生的人臉關鍵點以及人臉表情圖片則可用來生成虛擬音樂家的臉部模型參數。在運鏡模型中,我們沿用本研究團隊林仁俊博士開發的演唱會視覺敘事(visual storytelling)模型。為了將此模型應用在古典樂的音樂會影片上,我們額外建立了一個音樂會的鏡位資料庫供參數調整。至此,我們已經能夠進行虛擬音樂家演奏視訊生成系統整合,可以僅輸入音樂訊號,就能自動生成虛擬音樂家的演奏影片,如圖一。本系統的實測可見於本實驗室的公開網路直播影片〈工程師與虛擬音樂家們的線上音樂沙龍〉:https://www.youtube.com/watch?v=rVoDGc0dQ7g 。

從單鏡頭視頻中估計人物的三維姿勢與形體
在現行電腦生成的電影與動畫角色上,主要仰賴MOCAP系統這套穿戴裝置來捕捉人物的三維姿勢與形體。然而,一套專業的光學MOCAP裝置其售價皆在千萬以上,因此我們希望以電腦視覺的方法直接從拍攝到的影片中,逐幀地將人物的三維姿勢與形體估測出來,以降低電腦生成電影與動畫角色的成本。
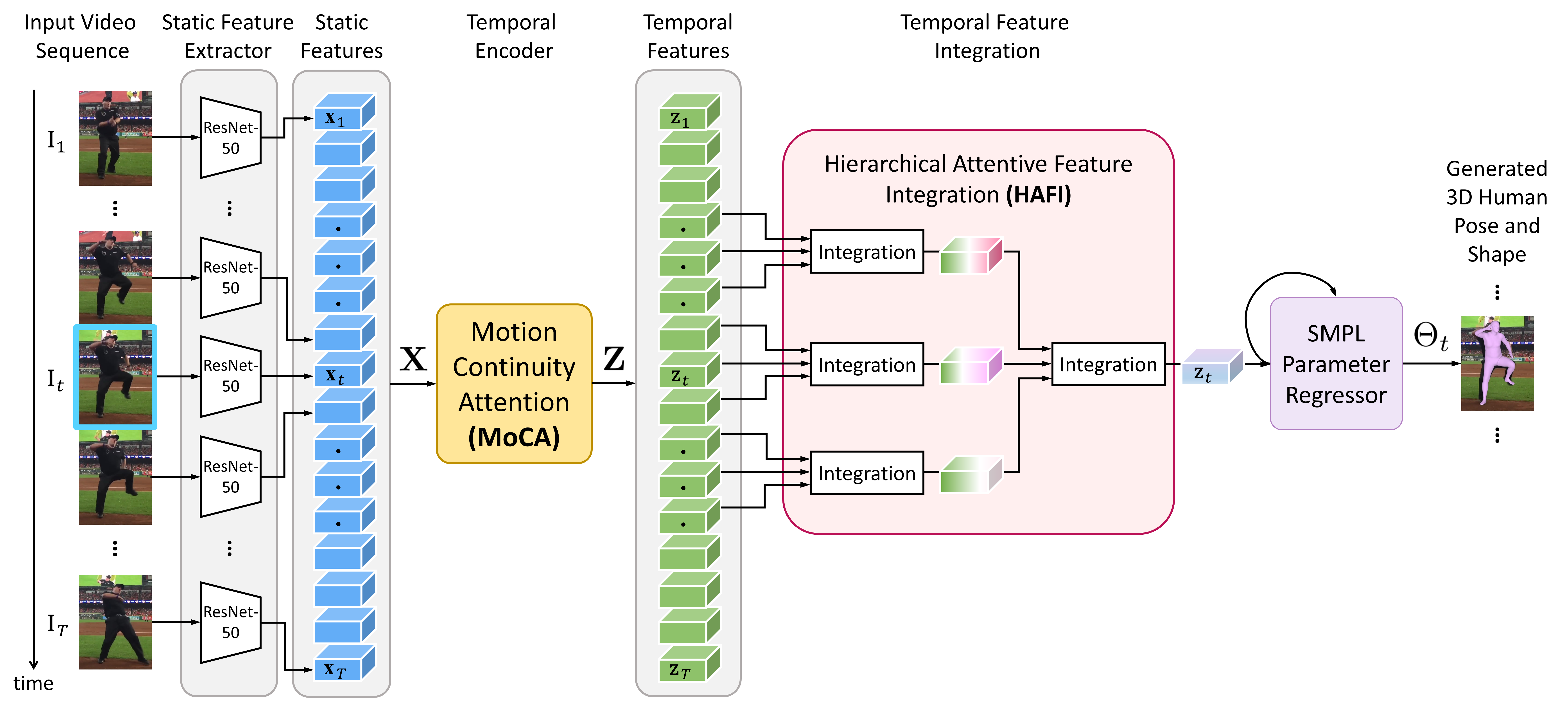
現行基於視訊的三維姿勢與形體估測方法,主要仰賴循環神經網路(Recurrent Neural Network; RNN)或卷積神經網絡(Convolutional Neural Network; CNN)來捕捉人體運動在時間上的變化。然而, RNN以及CNN僅擅於模組化(Model)鄰域(短期)的時間資訊,而無法有效地捕捉人體運動於時間上全域(長期)的變化。另一方面,現行的方法亦仰賴於使用更大的類神經網路架構來提升效能,而這也將限制該技術實際落實的機會。為此,我們提出了一個運動姿勢與形體網路(Motion Pose and Shape Network; MPS-Net),如圖二所示,透過設計兩種新式的注意力機制:運動連續性注意力(Motion Continuity Attention; MoCA)模塊以及階層式注意力特徵集成(Hierarchical Attentive Feature Integration; HAFI)模塊,來更好地模組化人體運動於時間上全域以及局部鄰域的關聯性。MPS-Net的參數量僅有state-of-the-art方法的三分之一,卻進一步提升了三維姿勢與形體估測的準確性。
如圖三,相較於現行state-of-the-art的方法,即Temporally Consistent Mesh Recovery (TCMR)系統,我們所提出的MPS-Net所估測出的三維姿勢與形體,特別在四肢上,可以更好地擬合在輸入影像中的人物身上。

圖四進一步顯示了將MPS-Net所估測出的三維人體動作套用在虛擬角色(Virtual Characters)上的成果,實現基於電腦視覺的三維人物動畫控制。更多的結果請參照https://mps-net.github.io/MPS-Net/。而這項工作的階段性成果發表在CVPR 2022。
